Transfer Learning for Image Classification in PyTorch



- How CNN Learns
- Creating a Custom Pytorch Dataset
- Creating Training and Validation Sets
- Modifying a Pretrained Model (ResNet34)
- GPU Utilities and Training Loop
- Finetuning the Pretrained Model
- Training a model from scratch
How CNN Learns
see CNN explainer - poloclub cnn
Pytorch CNN visualizations - very cool github
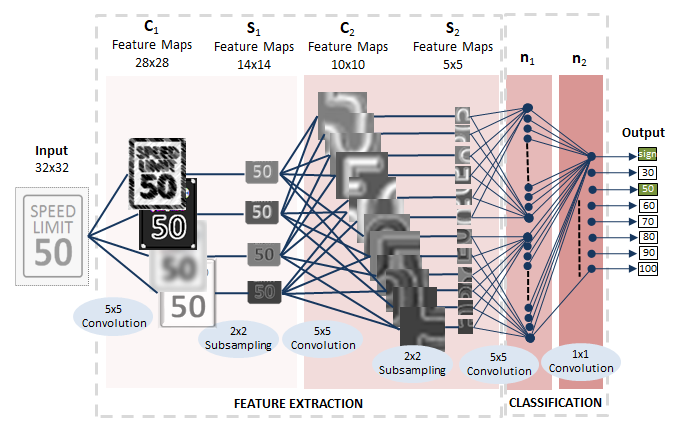
Layer Visualizations - 
CNN creates a layered understanding of data, Idea behind transfer learning is we take a CNN that has been already trained on a very large dataset (ex: Imagenet) ie. pretrained model, and we use some of the layers of these model to train custom models for a custom datasets that we are working with, so the features learned in those layers they are going to be useful for solving any image classifiation problem or any CV problem, the only needs to change is the classifier in the end
Dataset: Qxford-IIIT Pets dataset : https://www.robots.ox.ac.uk/~vgg/data/pets/
from torchvision.datasets.utils import download_url
download_url('https://s3.amazonaws.com/fast-ai-imageclas/oxford-iiit-pet.tgz','.')
import tarfile
with tarfile.open('./oxford-iiit-pet.tgz', 'r:gz') as tar:
tar.extractall(path='./data')
import os
DATA_DIR = './data/oxford-iiit-pet/images'
files = os.listdir(DATA_DIR)
files[:5]
def parse_breed(fname):
parts = fname.split('_')
return ' '.join(parts[:-1])
parse_breed(files[3])
from PIL import Image
def open_image(path):
with open(path, 'rb') as f:
img = Image.open(f)
return img.convert('RGB')
import matplotlib.pyplot as plt
plt.imshow(open_image(os.path.join(DATA_DIR,files[4])))

plt.imshow(open_image(os.path.join(DATA_DIR,files[500])))

from torch.utils.data import Dataset
# Dataset class needs 3 funcs to be implemented -- __init__, __len__, __getitem__
class PetsDataset(Dataset):
def __init__(self, root, transform):
super().__init__()
self.root = root
self.files = [fname for fname in os.listdir(root) if fname.endswith('.jpg')]
self.classes = list(set(parse_breed(fname) for fname in files))
self.transform = transform
def __len__(self):
return len(self.files)
def __getitem__(self, i):
fname = self.files[i]
fpath = os.path.join(self.root, fname)
img = self.transform(open_image(fpath))
class_idx = self.classes.index(parse_breed(fname))
return img, class_idx
import torchvision.transforms as T
img_size = 224
imagenet_stats = ([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # normalization stats that were used to normalize imagenet model
dataset = PetsDataset(DATA_DIR, T.Compose([T.Resize(img_size),
T.Pad(8, padding_mode='reflect'),
T.RandomCrop(img_size),
T.ToTensor(),
T.Normalize(*imagenet_stats)]))
len(dataset)
dataset.classes
len(dataset.classes)
import torch
torch.cuda.empty_cache()
import matplotlib.pyplot as plt
%matplotlib inline
def denormalize(images, means, stds):
if len(images.shape) ==3:
images = images.unsqueeze(0)
means = torch.tensor(means).reshape(1,3,1,1)
stds = torch.tensor(stds).reshape(1,3,1,1)
return images*stds + means
def show_image(img_tensor, label):
print('Label:', dataset.classes[label], '(' + str(label) + ')')
img_tensor = denormalize(img_tensor, *imagenet_stats)[0].permute((1, 2, 0))
plt.imshow(img_tensor)
show_image(*dataset[10])

show_image(*dataset[111])

from torch.utils.data import random_split
val_pct = 0.1
val_size = int(val_pct *len(dataset))
train_ds, valid_ds = random_split(dataset, [len(dataset) - val_size, val_size])
len(train_ds), len(valid_ds)
from torch.utils.data import DataLoader
batch_size = 64
train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)
valid_dl = DataLoader(valid_ds, batch_size*2, num_workers=4, pin_memory=True)
from torchvision.utils import make_grid
def show_batch(dl):
for images, labels in dl:
fig, ax = plt.subplots(figsize=(16, 16))
ax.set_xticks([]); ax.set_yticks([])
images = denormalize(images[:64], *imagenet_stats)
ax.imshow(make_grid(images, nrow=8).permute(1, 2, 0))
break
show_batch(train_dl)

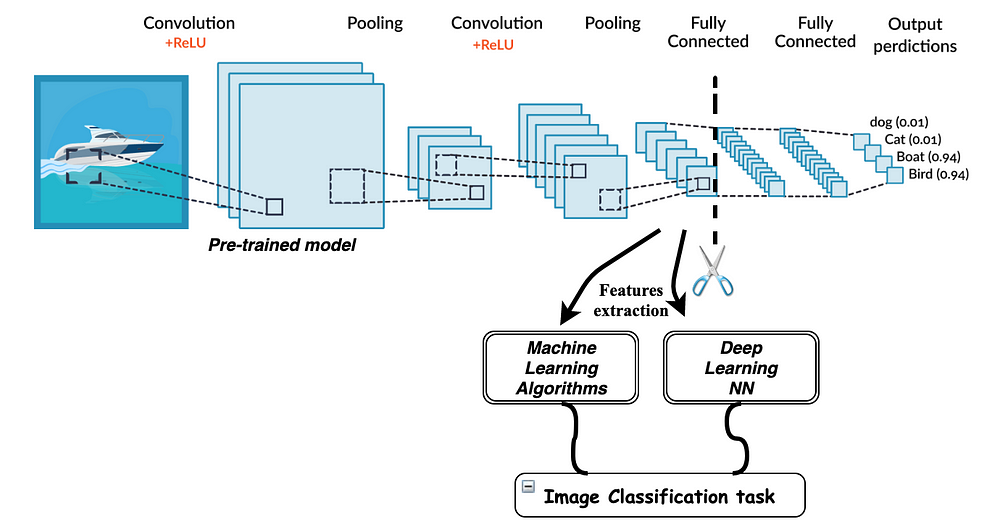
import torch.nn as nn
import torch.nn.functional as F
def accuracy(outputs, labels):
_, preds = torch.max(outputs, dim=1)
return torch.tensor(torch.sum(preds == labels).item()/ len(preds))
class ImageClassificationBase(nn.Module):
def training_step(self, batch):
images, labels = batch
out = self(images)
loss = F.cross_entropy(out, labels)
return loss
def validation_step(self, batch):
images, labels = batch
out = self(images)
loss = F.cross_entropy(out, labels)
acc = accuracy(out, labels)
return {'val_loss': loss.detach(), 'val_acc': acc}
def validation_epoch_end(self, outputs):
batch_losses = [x['val_loss'] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean()
batch_accs = [x['val_acc'] for x in outputs]
epoch_acc = torch.stack(batch_accs).mean()
return {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}
def epoch_end(self, epoch, result):
print("Epoch [{}], {} train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(
epoch, "last_lr: {:.5f}".format(result['lrs'][-1]) if 'lrs' in result
else '', result['train_loss'], result['val_loss'], result['val_acc']))
from torchvision import models
class PetsModel(ImageClassificationBase):
def __init__(self, num_classes, pretrained=True):
super().__init__()
#use a pretrained mode
self.network = models.resnet34(pretrained = pretrained)
#replace last layer
self.network.fc = nn.Linear(self.network.fc.in_features, num_classes)
def forward(self, xb):
return self.network(xb)
resnet = models.resnet34(pretrained=True) #condesed knowledge is captured and we got them bro we got them
resnet
def get_default_device():
"""Pick GPU if available, else CPU"""
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
def to_device(data, device):
"""Move tensor(s) to chosen device"""
if isinstance(data, (list, tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader():
"""Wrap a dataloader to move data to a device"""
def __init__(self, dl, device):
self.dl = dl
self.device = device
def __iter__(self):
"""Yield a batch of data after moving it to device"""
for b in self.dl:
yield to_device(b, self.device)
def __len__(self):
"""Number of batches"""
return len(self.dl)
import torch
from tqdm.notebook import tqdm
@torch.no_grad()
def evaluate(model, val_loader):
model.eval()
outputs = [model.validation_step(batch) for batch in val_loader]
return model.validation_epoch_end(outputs)
def fit(epochs, lr, model, train_loader, val_loader, opt_func=torch.optim.SGD):
history = []
optimizer = opt_func(model.parameters(), lr)
for epoch in range(epochs):
# Training Phase
model.train()
train_losses = []
for batch in tqdm(train_loader):
loss = model.training_step(batch)
train_losses.append(loss)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Validation phase
result = evaluate(model, val_loader)
result['train_loss'] = torch.stack(train_losses).mean().item()
model.epoch_end(epoch, result)
history.append(result)
return history
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def fit_one_cycle(epochs, max_lr, model, train_loader, val_loader,
weight_decay=0, grad_clip=None, opt_func=torch.optim.SGD):
torch.cuda.empty_cache()
history = []
# Set up custom optimizer with weight decay
optimizer = opt_func(model.parameters(), max_lr, weight_decay=weight_decay)
# Set up one-cycle learning rate scheduler
sched = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, epochs=epochs,
steps_per_epoch=len(train_loader))
for epoch in range(epochs):
# Training Phase
model.train()
train_losses = []
lrs = []
for batch in tqdm(train_loader):
loss = model.training_step(batch)
train_losses.append(loss)
loss.backward()
# Gradient clipping
if grad_clip:
nn.utils.clip_grad_value_(model.parameters(), grad_clip)
optimizer.step()
optimizer.zero_grad()
# Record & update learning rate
lrs.append(get_lr(optimizer))
sched.step()
# Validation phase
result = evaluate(model, val_loader)
result['train_loss'] = torch.stack(train_losses).mean().item()
result['lrs'] = lrs
model.epoch_end(epoch, result)
history.append(result)
return history
device = get_default_device()
device
train_dl = DeviceDataLoader(train_dl, device)
valid_dl = DeviceDataLoader(valid_dl, device)
model = PetsModel(len(dataset.classes), pretrained = True)
to_device(model, device);
history = [evaluate(model, valid_dl)]
history
epochs = 5
max_lr = 0.01
grad_clip = 0.1
weight_decay = 1e-4
opt_func = torch.optim.Adam
%%time
history += fit_one_cycle(epochs, max_lr, model, train_dl, valid_dl,
grad_clip = grad_clip,
weight_decay = weight_decay,
opt_func = opt_func)
torch.cuda.memory_summary(device=None, abbreviated=False)
model2 = PetsModel(len(dataset.classes), pretrained=False)
to_device(model2, device);
history2 = [evaluate(model2, valid_dl)]
history2
While the pretrained model reached an accuracy of 80% in less than 3 minutes, the model without pretrained weights could only reach an accuracy of 24%.